可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)是向大型语言模型(LLM)注入学习信号的主要训练策略之一,也是时下最主流的RL范式。DeepSeek R1 , Kimi K1.5, Tülu 3 都在后训练(Post-Training)中使用了这一套范式。
简单来说,可验证奖励是一些预定义好的指令和验证函数,它们在给定任务上提供清晰、二元的真实信号,通常是“1”(正确)或“0”(不正确),来指示模型的输出是否满足预定义任务的正确性标准。
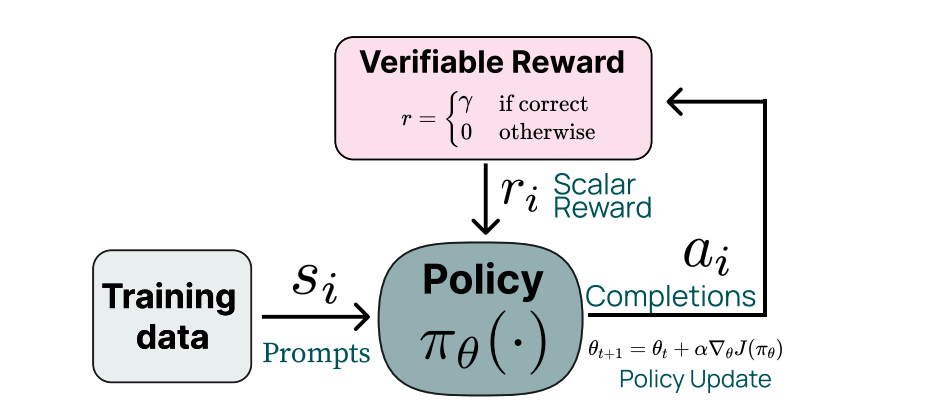
RLVR有哪些好处?
与RLHF中使用的偏好奖励函数不同,可验证奖励具有以下几个优势:
客观真实
所有的任务都有客观真实的答案(Ground Truth),与模型效果有着直接、无偏见的目标联系,使其成为数学问题解决和代码执行等高精度、客观任务的理想选择。
易于设计和评估
可验证奖励提供了一种快速简便的方法来设计稳定可靠的强化学习环境,使领域专家能够建立明确的正确性标准,而无需深厚的机器学习专业知识。其明确的性质有助于自动化评估,最大限度地减少对人类判断的依赖,并确保高效、可扩展地集成到强化学习流程中。
防止奖励“作弊”
由于可验证奖励依赖于严格的、基于规则的评估,而不是学习到的近似值,因此 LLM “作弊”的空间很小。通过二元指标,模型不会因为输出仅表面上符合标准而获得部分奖励。本质上,可验证奖励充当了一个直接的“是/否”门,告知学习算法特定输出是否满足必要条件,从而通过提供明确的反馈来简化训练过程。
RLVR的类型
所有的自动化Benchmark都天然符合RLVR的范式,但是强烈建议不要用开源benchmark做RLVR。
以下是一些开源数据集示例:
数学
GSM8K
GSM8K(Grade School Math 8K) 是一个由 OpenAI 创建的高质量数据集,包含了约 8500 个小学水平的数学应用题。这些问题旨在测试模型进行多步数学推理的能力。"GSM8K" 中的 "8K" 代表数据集中大约有 8000 个问题。这些数学问题通常需要 2 到 8 个步骤来解决,并且只涉及基本的算术运算(加、减、乘、除)。问题的设计具有相当的多样性,覆盖了小学数学课程中的各种场景。
数据格式与示例
question: (字符串) 数学应用题的文本描述。answer: (字符串) 包含详细解题步骤和最终答案的文本。解题步骤以自然语言形式给出,最终答案通常以#### <数字>的格式标记在解答的末尾。
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72",
}
RLVR过程
- 将
question输入模型,获得output - 提取出answer中
####后的<数字>部分作为正确答案 - 对比
output与<数字>是否一致1: 答案一致0: 答案不一致
MATH
MATH 数据集是一个用于评估机器模型数学问题解决能力的基准。它包含了 12,500 个具有挑战性的竞赛数学问题,涵盖从初中到高中(甚至一些大学预科)水平的数学内容。与 GSM8K 主要关注小学算术不同,MATH 数据集旨在测试更高级别的数学推理能力,要求模型不仅能进行计算,还需要理解和应用更广泛的数学概念和技巧。
这些问题来源于 AMC 10, AMC 12, AIME (美国数学邀请赛) 等数学竞赛,以及其他数学竞赛和教科书。每个问题都附带有详细的、逐步的 LaTeX 格式解答。
数据格式与示例
problem: (字符串) 数学应用题的文本描述。solution: (字符串) 使用 LaTeX 编写的详细解题步骤。最终答案通常包含在\boxed{<answer>}中。

代码执行
在 LLM 用于生成代码的场景中,RLVR需要一个可以运行代码的沙盒环境,环境中应包含完成指定代码任务所必要的依赖。验证函数通过对模型生成代码在指定环境中的运行结果/单元测试结果/异常信息来给定Reward。
示例:
+1: 所有测试通过-1: 所有测试失败-0.2:如果部分测试通过
HumanEval
HumanEval 数据集包含 164 个手写编程问题。这些问题旨在评估模型的语言理解能力、算法知识和简单的数学逻辑,有些问题类似于简单的软件面试题。创建该数据集的一个重要原因是,许多代码生成模型在 GitHub 的代码库上进行训练,因此需要一个不包含在该训练数据中的评估集,以准确衡量模型的真实能力。不过,由于该数据集已公开发布在 GitHub 上,未来也可能被包含在训练数据中。
数据格式与示例
task_id: 任务的唯一标识符,通常包含任务所属的语言和编号 (例如 "HumanEval/0" 或 "Java/0")。prompt: 模型的输入,通常包含函数签名、docstring 以及可能的示例用法。用自然语言描述了函数应该实现的功能。canonical_solution: 一个手写的、正确的函数实现,作为参考答案。test: 一系列的单元测试用例,用于自动评估模型生成的代码是否正确。entry_point: 测试用例的入口函数名称。
{
"task_id": "test/0",
"prompt": "def return1():\n",
"canonical_solution": " return 1",
"test": "def check(candidate):\n assert candidate() == 1",
"entry_point": "return1"
}
指令遵循和格式化
这些奖励评估 LLM 输出是否严格遵守给定的指令或指南。
通常这可以通过简单的字符串匹配或者格式解析工具来完成。
示例: 在模型响应中,应满足以下标准之一:
- 在您的响应中包含关键字
{keyword1}、{keyword2} - 将推理过程放在
<think>和</think>标签之间。 - 必须按照某个json schema输出(Function calling)
其他类别
随着模型能力提升,RLVR可用的领域也变得越来越复杂多样。以下列举一些复杂的Benchmark:
Computer Use
- OSWorld:用于多模态Agent在真实计算机环境中执行开放式任务的基准测试集以及对应的模拟环境
- 评估集中提供了一系列包含 <指令,环境准备,结果评估> 的任务以及对应的评估函数
- 模拟环境包含了指令空间、系统镜像、应用程序,以确保每次模型都从一个稳定的初始环境开始评估
- WindowsAgentArena:由Microsoft官方提供的用于测试多模态Agent在Windows系统下的基准测试集,提供与OSWorld类似的评估方法
Browser Use
- WebCanvas:Web Agents在线评估框架,用于衡量Agent在动态变化的网络环境中的表现
- Mind2Web-Live 基准数据集:基于Mind2Web改进的数据集,将原有静态网站snapshot替换成真实世界的网页
- 过程评估与关键节点:评估函数中包含了最终结果与关键过程,一来降低来自真实环境的噪音,二来某种程度上避免了过程“作弊”
- 开源可扩展的Web Agent框架:提供指令空间/browser环境,便于模型接入以及自定义benchmark设计
Phone Use
- AndroidWorld:由 Google Research 开发的环境和基准测试平台,专用于构建和评估Phone Use Agent
- 真实的 Android 环境: AndroidWorld 运行在真实的 Android 模拟器上,为代理提供了一个与现实世界应用交互的环境。
- 动态和可复现的任务: 包含横跨20个真实 Android 应用的116个精心设计的任务模版。可以通过随机生成的参数创建数百万个独特的任务变体,从而能够进行更全面和真实的测试。
- 开源和可扩展: 该项目框架是开源的,所有人都可以在框架内添加新的任务和基准。
如何构建RLVR
构建RLVR需要专业知识、领域专长和优秀的工程能力。这确保了强化学习系统能够准确判断高质量输出并进行自我迭代,同时避免偏见和失准。
数据集准备
- 利用专家知识: 与领域专家合作,定义什么是正确或高质量的奖励。
- 使用高质量数据集: 从公开来源、合成或人工标注中收集可靠的带有标注的数据集。
- 数据去污: 确保数据集不与评估基准重叠,以防止过拟合。
- 多样化采样: 收集涵盖广泛场景的数据,确保泛化能力。
定义奖励函数
- 定义验证标准: 确定具有可验证结果的任务,例如数学证明、代码执行、指令遵守或特定领域的目标。
- 精确匹配: 使用确定性规则检查正确性(例如,数学答案中的精确匹配、代码中通过测试用例、匹配预定义的类别或分类法等)。
- 避免基于模型的奖励: 优先使用基于规则的奖励函数,而不是模型驱动的奖励函数,以减少奖励“作弊”并确保可靠性。可以使用由自然语言明确定义的规则,搭配模型辅助奖励计算来平衡宽容度和精确度。
- 多级评分: 在合适的场景下使用分层评分机制以奖励部分正确性,避免奖励过于稀疏影响迭代效率。
测试并验证奖励
- 运行受控测试: 在稳定环境下生成模型输出并衡量奖励函数对正误输出的区分度。
- 评估规则鲁棒性: 确保函数不会因为格式问题或微小差异而惩罚正确的响应。
- 进行 A/B 测试: 比较使用和不使用RLVR训练的模型之间的性能。
RLVR的局限性
- 强依赖特定领域的奖励验证规则和验证器的实现,应用范围受限,难以低成本泛化。
- 可能导致模型通用性降低,能力边界收窄,成为某一特定领域的专用模型。
- 未经良好设计的奖励反馈可能使模型产生路径依赖与探索能力下降。
What's Next?
回到 The Second Half, 定义模型落地的场景,定义有挑战的问题,定义清晰的评估体系。
✨ Copilot with Gemini 2.5 Pro ✨