Rubric 第二讲:深入了解不同类型的 rubric 及其使用场景
你知道要衡量什么,但该如何衡量呢?
本文是 一面千识研究院 评分量表(rubric)系列博客中的第二篇。在本文中,我们将系统介绍评分量表的主要类型,包括:
- 数据集级评分量表:适用于所有提示词,强调通用性与可复用性;
- 实例特定型评分量表:与具体提示词同步设计,只适用于该实例,强调精准与定制化。
同时,我们会区分过程评估(trace 级)与结果评估的差异,并简要分析基于大语言模型的自动化评估与基于代码的可执行评估各自的特性与使用场景。
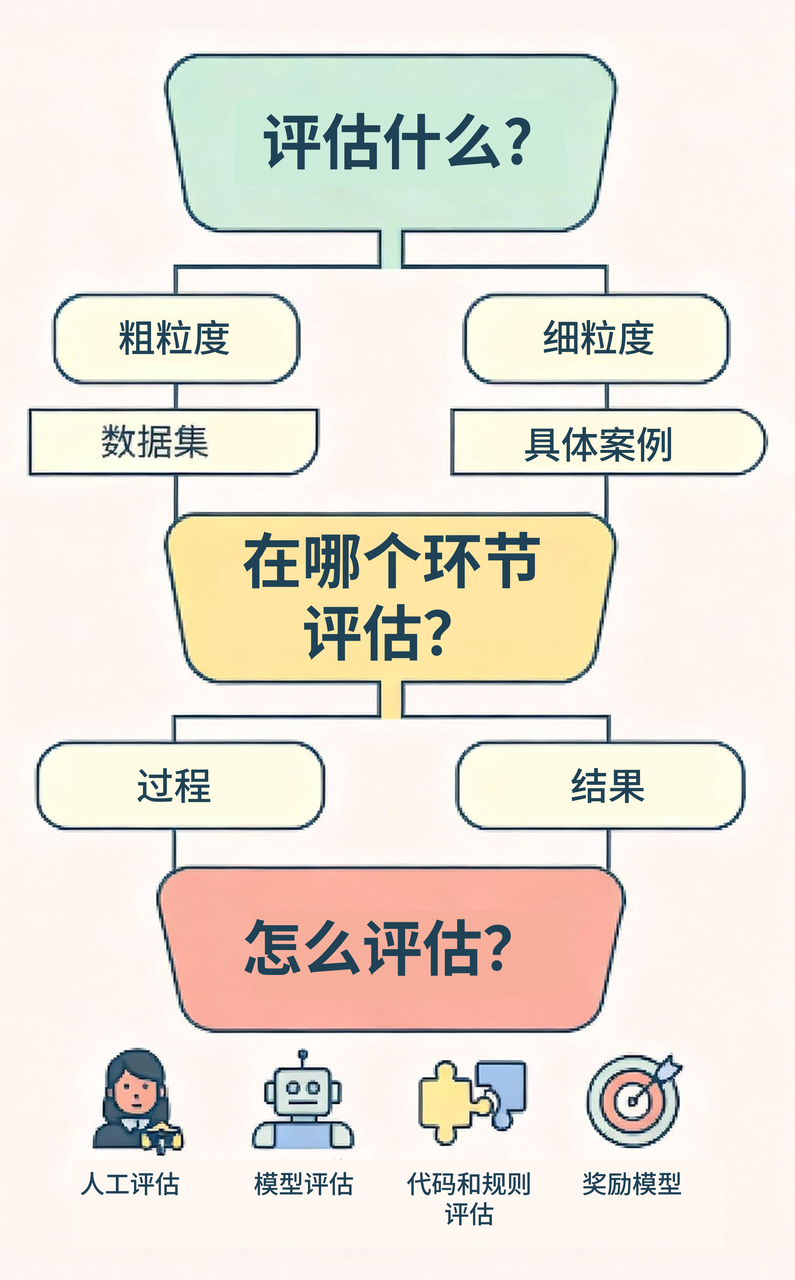
本文将解答三个核心问题:
- 衡量什么?(颗粒度 vs 特异性)
- 在哪里衡量?(过程 vs 结果)
- 如何衡量?(大语言模型 vs 代码)
生成式人工智能(GenAI)系统的 “黑箱” 特性,使其在真实环境中的表现虽非完全不可预测,却始终充满不确定性。要让 AI 产品从概念验证(POC)真正走向生产,就必须对其输出建立足够信心:它是否高效、是否安全、是否准确?
对于正确性定义清晰、易于验证的任务,系统性能与输出质量可通过 “黄金标准答案” 来衡量 —— 例如,具有可计算数值答案的数学问题,或可执行且能通过一组人工设计单元测试的生成代码。
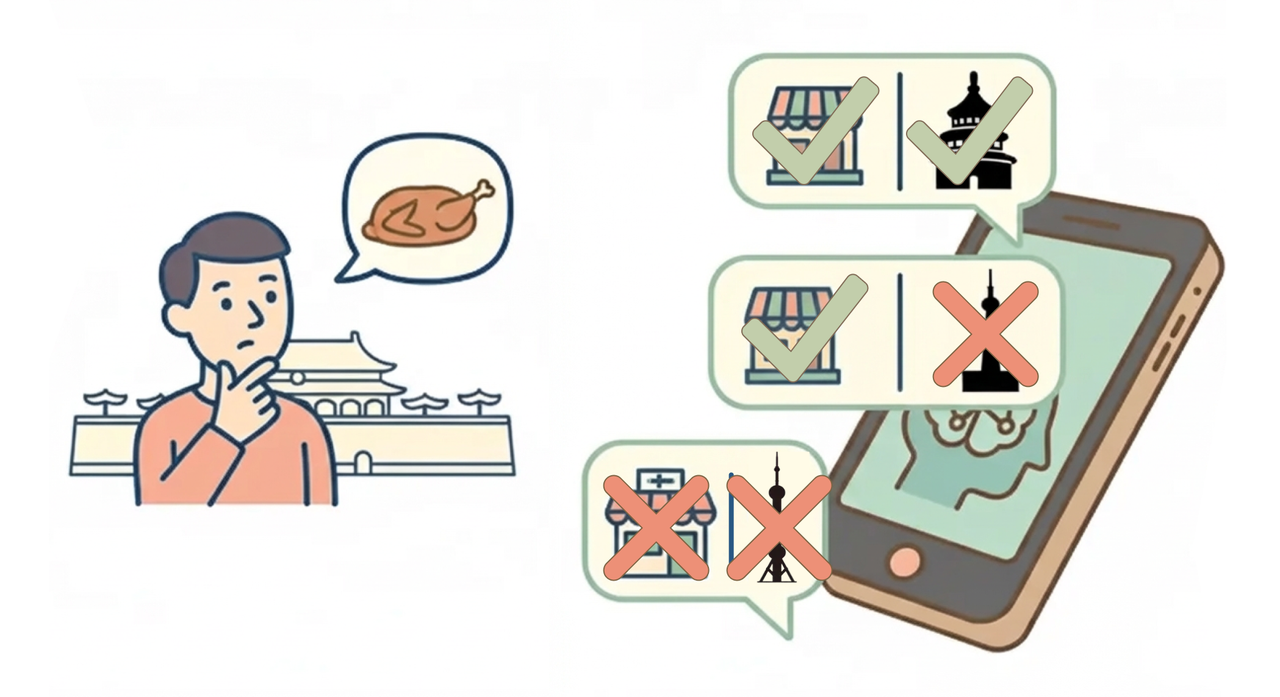
但在真实世界中,大多数任务并没有这样明确的边界。“优质回答”与“劣质回答”往往没有客观的唯一标准,尤其是在回答带主观性、开放性更强的问题时,这种判断难度会进一步加大。例如,问题 “北京最好的烤鸭店是哪家?” 并不存在公认的最佳答案,但我们仍可通过特定标准评估响应质量:推荐的餐厅是否提供烤鸭?该餐厅是否位于北京?这类场景说明:当无法依赖标准答案时,我们就必须依赖清晰、结构化、可复用的评分量表(Rubric),来系统化地衡量模型质量。
在系列第一篇博客中,我们介绍了“评分量表(Rubric)评估”这一关键技术——它帮助我们以一致、可靠的方式衡量生成式人工智能系统的响应质量。评分量表通过把“好”、“差”的回答拆解成清晰的维度与可衡量的要素,减少主观判断或偏见。尽管制定高质量评分量表需要投入大量时间,例如邀请领域专家梳理和明确关键要素,但这类投入能够明显提升人工标注者之间的一致性,也能让自动化评估方法,尤其是基于大语言模型的评判方式,更加稳定和可靠[1]。
一、衡量什么?
设计评分量表时,需要从两个维度做决策:颗粒度与特异性。它们共同决定评估能提供多少信息,以及制定标准所需的投入。
1. 颗粒度
- 粗粒度:例如简单的点赞或点踩,只判断好或不好。成本低、操作直观,适合早期筛选,但缺乏诊断力。
- 细粒度:将质量拆分为如流畅度、风格、正确性、实用性等独立维度。能揭示模型的具体优势与弱点,也有助于诊断问题,但设计与标注成本更高。
2. 特异性
当这些维度进一步细化为可操作的评分量表时,需要决定其适用范围:
- 数据集级评分量表:适用于所有提示词(如 HHH、FLASK 技能维度)。能规模化,但不够精准。
- 实例特定评分量表:专门为某个提示词设计(如 HealthBench、PaperBench),内容更具体且带有针对性。
通常,评分量表越具体,标注者之间越容易保持一致,因为明确的指令能减少误解与模糊空间;与此同时,制定这类标准所需的成本也更高。
 评分量表全景
评分量表全景
二、在哪里衡量?
前文我们讨论了评分量表的 "衡量内容"。接下来的设计问题是:评估应关注模型生成答案的过程,还是仅关注最终产出的结果?
在生成式模型日益承担复杂任务的背景下,这一区分尤其关键:
- 简单任务:仅看结果往往足够。
- 多步推理 / 工具使用 / 规划任务:必须检查过程,否则无法定位错误来源,也难以提升系统可靠性。
1. 基于过程的评分量表
该评分量表评估模型在得出最终答案前产生的推理步骤、中间状态或决策路径。关注的不是 “答案是什么”,而是 “答案是怎么来的”。
例如 ProcessBench[4](过程基准测试) 会逐步检查:
- 推理步骤是否连贯?
- 工具调用是否合理?
适合多步推理、智能体(agent)任务。
评分量表示例:
- 数学推理:“每个中间步骤的算术运算,是否能从上个步骤合理推导得出?”(0/1 分)
- 智能体工作流:“模型在起草答案前,是否尝试检索了相关文档?”(0/1 分)
2. 基于结果的评分量表
该评分量表只评估最终输出,不审查推理过程。当"质量可以从最终答案直接判断"时,这类评分方式更简单、成本更低,也更容易规模化。
例如“CriticGPT”[8](评论型大语言模型)是典型的 “结果导向“评估器。它无需追踪推理步骤,而是直接以事实性、连贯性、风格等维度评价最终输出;在深度研究任务[7] 等任务中,基于结果的评分量表注重最终交付质量。
评分量表示例:
- 最终答案正确性:“方程的解在数值上是否正确?”(0/1 分)
- 引用覆盖度:“报告中的每个关键主张,是否包含可验证的引用?”(0/1 分)
三、如何衡量?
前文讨论了评分量表的 "衡量内容"与 "衡量环节"。最后一步,是落到执行层面:谁来应用这些评分量表?
现实中主要有四类评估方式:人工评估、以大语言模型为评判者(LLM-as-a-judge)、基于代码或规则的评估,以及奖励模型。每种方式各有优势、权衡与成本。
1. 人工评估
- 定义:由领域专家或受训标注者直接应用评分量表,对模型输出做判断。
- 优势:精细判断的黄金标准,特别适用于医疗、法律等高风险领域;能确保评估与人类真实价值观对齐。
- 劣势:成本高、速度慢,且标注者之间可能出现分歧;需要通过精心设计的评分量表提升一致性、降低偏见。
- 最佳场景:复杂、主观或安全关键型任务。
- 示例(HealthBench[3]):“在紧急病例中,响应是否在开头明确建议立即就医?”——该判断需要临床专家才能可靠完成。
2. 以大语言模型为评判者(LLM-as-a-judge)
- 定义:由大语言模型自动应用评分量表,从指定维度对输出进行评分。
- 优势:成本低、速度快,适合大规模评估;在精心提示设计下,可捕捉流畅度、连贯性、语气等细节,表现与人类高度相关。
- 劣势:容易受模型偏见影响,对提示词敏感;在超出训练域的任务中可靠性下降;需要人类定期校准。
- 最佳场景:大规模基准测试、产品迭代周期;人类审查只用于校准与抽样。
- 示例(G-Eval[1]):“从 0-5 分给响应的事实准确性打分。”——GPT-4 等大语言模型可在几分钟内,将这一标准应用于数千条输出。
3. 基于代码或规则的评估
- 定义:通过确定性逻辑自动评估,如运行代码、执行单元测试、检查与黄金标准结果是否匹配。
- 优势:客观、可重复;若存在黄金答案,精度极高。
- 劣势:仅适用于正确性严格可定义的领域;无法评估风格、推理质量等主观因素。
- 最佳场景:编程、数学、数据提取等结构化任务。
- 示例:“提交的函数是否通过了所有提供的单元测试?”(0-n 分,n 为单元测试总数)。
4. 基于奖励模型的评估
- 定义:训练 "学习型评估工具(奖励模型)",使其输出接近人类偏好或评分量表判断,再规模化应用。
- 优势:能编码复杂偏好结构,且可复用;适合强化学习与智能体微调等场景。
- 劣势:训练需要大量高质量标注;可能嵌入标注者偏见;目前仍属新兴技术。
- 最佳场景:长期、大规模的自动化评估与反馈循环。
- 示例(WEAVER):“给定多个候选响应,根据‘有用性、事实性、无害性’对它们进行排序。”
结语
基于评分量表的评估并不是简单地区分好与坏,而是在做一系列经过深思熟虑的设计选择:在什么粒度上评估、在任务的哪个阶段评估、又采用何种方式进行评估。简言之:不存在 "通用最优" 的评分量表,一切均需结合场景。
References
- Liu, Yang, et al. “G-Eval: NLG evaluation using GPT-4 with better human alignment (2023).” arXiv preprint arXiv:2303.16634 12 (2023).
- Ye, Seonghyeon, et al. “Flask: Fine-grained language model evaluation based on alignment skill sets.” arXiv preprint arXiv:2307.10928 (2023).
- Arora, Rahul K., et al. “HealthBench: Evaluating large language models towards improved human health.” arXiv preprint arXiv:2505.08775 (2025).
- Zheng, Chujie, et al. “ProcessBench: Identifying process errors in mathematical reasoning.” arXiv preprint arXiv:2412.06559 (2024).
- Bai, Yuntao, et al. “Constitutional AI: harmlessness from AI feedback. 2022.” arXiv preprint arXiv:2212.08073 8.3 (2022).
- Starace, Giulio, et al. “PaperBench: Evaluating AI’s ability to replicate AI research.” arXiv preprint arXiv:2504.01848 (2025).
- “Introducing Deep Research.” OpenAI, OpenAI, 2 Feb. 2025, https://openai.com/index/introducing-deep-research/. Accessed 23 Aug. 2025.
- “Finding GPT‑4’s mistakes with GPT‑4.” OpenAI, 27 June 2024, https://openai.com/index/finding‑gpt4s‑mistakes‑with‑gpt‑4/. Accessed 23 Aug. 2025.
- Kim, Seungone, et al. “Prometheus: Inducing fine-grained evaluation capability in language models.” The Twelfth International Conference on Learning Representations. 2023.
- Saad-Falcon, Jon, et al. “Shrinking the generation-verification gap with weak verifiers.” arXiv preprint arXiv:2506.18203 (2025)