质量和速度一定是矛盾的吗?
本文是 一面千识研究院 关于 Rubric(评分量表)的系列博客中的第四篇。在大模型的世界里,“质量”常常被讨论,却没有人能定义清楚。我们常说数据是模型能力的源头,但究竟什么样的数据才算“优质”?不同业务场景、不同风险偏好、不同价值目标下,答案从来不是一种。
在一面千识研究院,我们长期与前线业务团队、算法研发与行业专家一起打磨数据流程,也在不断反思一个看似简单的问题: 如何既保证质量,又保持规模化交付的速度? 在 AI 数据管道里,规模化和高质量常常像天平两端,总有一个要牺牲。但在我们看来,这不是不可调和的矛盾,而是一门可以系统优化的学问。
传统质量控制的痛点
随着 LLM 从实验设计走向生产,数据标注量动辄百万。数据质量不能等到模型出问题再补救,它必须从项目开始就深深嵌入每个环节,从需求定义起步,经过评分量表的设计与验证校准,一路延伸到大规模生产和持续反馈循环。这套方法帮助我们在快速推进时,保持对数据可靠性的关注,避免质量随着规模扩大而滑坡。
回顾传统方法,专家抽检加人工复核听起来可靠,但实际问题不少:
- 主观性强,每个人对“高质量”的理解不同,一个标注员觉得细节够了,另一个可能觉得忽略了边际情况;
- 成本高,全量人工审核在数据量大时几乎不可行;
- 反馈迟缓,问题通常要等到模型上线、用户反馈或业务影响出现后才发现。
这些问题让我们意识到,需要将质量从“事后补救”转变为“全流程管理”,从源头设计可靠机制。
评分量表就是这个管理过程的核心,它像基础框架一样定义了数据管道的质量标准,帮助我们在质量保证和运营效率间寻求平衡。质检不应该被视为一次性任务,而是系统化处理,将主观判断转为结构化、可重复的指标。这样,我们能清楚区分数据集质量,还能量化 ROI,让客户看到高质量数据如何提升下游模型性能。归根结底,这是一种让信任可复制、可扩展的实践方式。
我们的质量流程闭环:从需求到反馈的四阶段实践
为了让评分量表真正落地,我们构建了一个多阶段质量管道,每个阶段环环相扣,评分量表作为连接一切的枢纽。从下图可以看到,整个流程从需求定义起步,一路到规模化持续反馈,形成闭环。
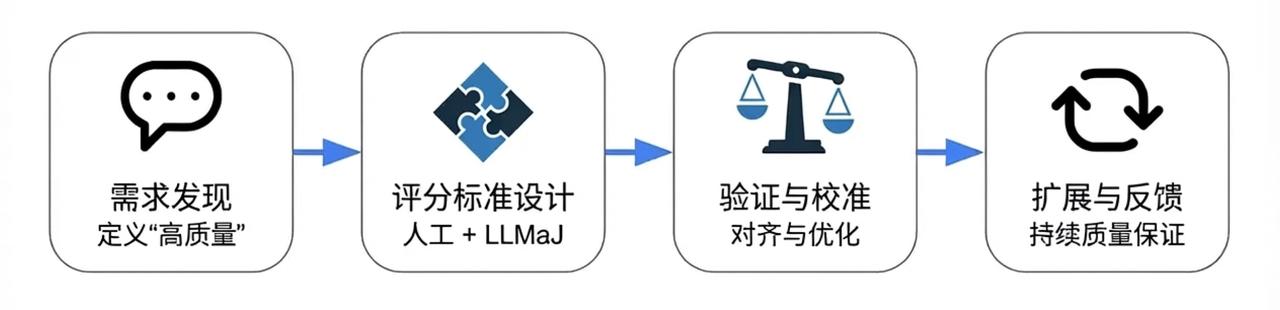
一、从需求开始:定义“好数据”的标准
每一个项目都应该从深入理解场景开始。
我们会和合作方并肩,一起厘清:
- 数据将如何用于训练?用于提升何种能力?
- 在这一具体领域里,“高质量”意味着什么?
- 哪些错误和幻觉在生产环境中会造成最大的问题?
这些问题构成了第一版评分量表的雏形。它不是一个静态文档,而是会随着反馈、迭代和对场景理解不断加深完善的系统。
二、共同设计:把专业判断转化为可执行的结构
评分量表的设计,是一个需要“翻译”的过程。
它要同时满足两个看似矛盾的要求:
- 标注员能读懂并准确执行
- 又足够严谨,能体现任务中那些细微但关键的质量维度
我们通常与领域专家、数据团队共同定义标准,结合:
- 通用指标(如连贯性、事实一致性)
- 场景特定标准(如承保规则、金融风控条件、代码判断依据)

此外,我们还会明确哪些部分适合机器审核(LLMaJ)自动化处理,哪些必须人工审核。同时,把通用指标如指令遵循和无害性,与特定领域检查如保险承保标准相结合,让评分量表既广又深。
三、验证与校准:把主观判断校成共同语言
在规模化投入使用之前,所有评分量表都必须经历一段压力测试。
这通常包括:
- 培训专家标注员和审核员,让大家对标准的理解趋同
- 通过黄金样本校准不同评审者的判断
- 对比模型评审与人工评分的吻合度
- 针对模糊表述重新修订,使审核员之间的一致率稳定提升
在一些项目里,仅通过过优化评分量表的表述,人机之间的一致性就提升了 30–50%。 这一步并不轻松,但决定了规模化阶段的稳定性。
四、规模化生产:让质量体系真正“落地”
经过校准的评分量表会被应用到正式的标注与审核流程中。
经典的流程包括:
- 基于 LLM、规则或代码的定制打分
- 大模型批量处理 + 人工抽检复核
- 基于质检反馈不断调整提示词、修订标准
一旦验证通过,评分量表就进入规模化扩展与持续反馈阶段。我们使用基于 LLM 或代码的定制评估器来辅助专家对 LLMaJ 处理批量评估的结果进行校准;所有审核结果实时反馈回评分量表改进和 LLMaJ 提示词调优,让多人、多环节、多工具协同时仍能保持一致的质量基线。
结语:可复用的质检流程
为了确保评分量表真正发挥作用,我们内部遵循一套可复用的流程:
- 定义什么是高质量:将业务目标具体化为可衡量的标准
- 设计评分量表:将专家经验结构化
- 验证与校准:让模型与人工评分趋于一致
- 规模化部署:投入生产,并持续收集反馈
- 衡量影响:追踪一致率、覆盖率与任务表现
- 实验与迭代:用 A/B 测试驱动持续优化
在我们看来,基于评分量表的评估是规模化构建信任的支柱。一面千识研究院选择用评分量表体系,通过结合严谨的设计、协作式验证和持续改进,把质量设计进整个数据生命线。高质量不会凭空出现,它来自结构、方法论,以及对行业的长期理解。
质量和速度一定是矛盾的吗?
本文是 一面千识研究院 关于 Rubric(评分量表)的系列博客中的第四篇。在大模型的世界里,“质量”常常被讨论,却没有人能定义清楚。我们常说数据是模型能力的源头,但究竟什么样的数据才算“优质”?不同业务场景、不同风险偏好、不同价值目标下,答案从来不是一种。
在一面千识研究院,我们长期与前线业务团队、算法研发与行业专家一起打磨数据流程,也在不断反思一个看似简单的问题: 如何既保证质量,又保持规模化交付的速度? 在 AI 数据管道里,规模化和高质量常常像天平两端,总有一个要牺牲。但在我们看来,这不是不可调和的矛盾,而是一门可以系统优化的学问。
传统质量控制的痛点
随着 LLM 从实验设计走向生产,数据标注量动辄百万。数据质量不能等到模型出问题再补救,它必须从项目开始就深深嵌入每个环节,从需求定义起步,经过评分量表的设计与验证校准,一路延伸到大规模生产和持续反馈循环。这套方法帮助我们在快速推进时,保持对数据可靠性的关注,避免质量随着规模扩大而滑坡。
回顾传统方法,专家抽检加人工复核听起来可靠,但实际问题不少:
- 主观性强,每个人对“高质量”的理解不同,一个标注员觉得细节够了,另一个可能觉得忽略了边际情况;
- 成本高,全量人工审核在数据量大时几乎不可行;
- 反馈迟缓,问题通常要等到模型上线、用户反馈或业务影响出现后才发现。
这些问题让我们意识到,需要将质量从“事后补救”转变为“全流程管理”,从源头设计可靠机制。
评分量表就是这个管理过程的核心,它像基础框架一样定义了数据管道的质量标准,帮助我们在质量保证和运营效率间寻求平衡。质检不应该被视为一次性任务,而是系统化处理,将主观判断转为结构化、可重复的指标。这样,我们能清楚区分数据集质量,还能量化 ROI,让客户看到高质量数据如何提升下游模型性能。归根结底,这是一种让信任可复制、可扩展的实践方式。
我们的质量流程闭环:从需求到反馈的四阶段实践
为了让评分量表真正落地,我们构建了一个多阶段质量管道,每个阶段环环相扣,评分量表作为连接一切的枢纽。从下图可以看到,整个流程从需求定义起步,一路到规模化持续反馈,形成闭环。
一、从需求开始:定义“好数据”的标准
每一个项目都应该从深入理解场景开始。
我们会和合作方并肩,一起厘清:
- 数据将如何用于训练?用于提升何种能力?
- 在这一具体领域里,“高质量”意味着什么?
- 哪些错误和幻觉在生产环境中会造成最大的问题?
这些问题构成了第一版评分量表的雏形。它不是一个静态文档,而是会随着反馈、迭代和对场景理解不断加深完善的系统。
二、共同设计:把专业判断转化为可执行的结构
评分量表的设计,是一个需要“翻译”的过程。
它要同时满足两个看似矛盾的要求:
- 标注员能读懂并准确执行
- 又足够严谨,能体现任务中那些细微但关键的质量维度
我们通常与领域专家、数据团队共同定义标准,结合:
- 通用指标(如连贯性、事实一致性)
- 场景特定标准(如承保规则、金融风控条件、代码判断依据)
此外,我们还会明确哪些部分适合机器审核(LLMaJ)自动化处理,哪些必须人工审核。同时,把通用指标如指令遵循和无害性,与特定领域检查如保险承保标准相结合,让评分量表既广又深。
三、验证与校准:把主观判断校成共同语言
在规模化投入使用之前,所有评分量表都必须经历一段压力测试。
这通常包括:
- 培训专家标注员和审核员,让大家对标准的理解趋同
- 通过黄金样本校准不同评审者的判断
- 对比模型评审与人工评分的吻合度
- 针对模糊表述重新修订,使审核员之间的一致率稳定提升
在一些项目里,仅通过过优化评分量表的表述,人机之间的一致性就提升了 30–50%。 这一步并不轻松,但决定了规模化阶段的稳定性。
四、规模化生产:让质量体系真正“落地”
经过校准的评分量表会被应用到正式的标注与审核流程中。
经典的流程包括:
- 基于 LLM、规则或代码的定制打分
- 大模型批量处理 + 人工抽检复核
- 基于质检反馈不断调整提示词、修订标准
一旦验证通过,评分量表就进入规模化扩展与持续反馈阶段。我们使用基于 LLM 或代码的定制评估器来辅助专家对 LLMaJ 处理批量评估的结果进行校准;所有审核结果实时反馈回评分量表改进和 LLMaJ 提示词调优,让多人、多环节、多工具协同时仍能保持一致的质量基线。
结语:可复用的质检流程
为了确保评分量表真正发挥作用,我们内部遵循一套可复用的流程:
- 定义什么是高质量:将业务目标具体化为可衡量的标准
- 设计评分量表:将专家经验结构化
- 验证与校准:让模型与人工评分趋于一致
- 规模化部署:投入生产,并持续收集反馈
- 衡量影响:追踪一致率、覆盖率与任务表现
- 实验与迭代:用 A/B 测试驱动持续优化
在我们看来,基于评分量表的评估是规模化构建信任的支柱。一面千识研究院选择用评分量表体系,通过结合严谨的设计、协作式验证和持续改进,把质量设计进整个数据生命线。高质量不会凭空出现,它来自结构、方法论,以及对行业的长期理解。