SETA(Camel-AI 发布):号称全自动生成与验证的 SOTA 级合成数据集。地址:https://github.com/camel-ai/seta-env/
本文基于对 SETA 数据集中12个Terminal Bench任务审查,补充梳理出一些高频质量问题。它们主要集中在指令与测试不对齐、环境构造失真、验证粒度不足、题目信息泄露过度,以及关键能力未被有效考察等方面。对于RLVR的训练范式而言,这类缺陷会直接污染 Reward 信号,误导模型优化方向。
背景与分析目标
RLVR是一类依赖可自动验证结果进行优化的训练方法,在代码生成、终端操作和智能体任务中应用广泛。对于这类方法,测试脚本不仅用于评测模型表现,也直接决定奖励信号的生成方式。换句话说,任务指令、执行环境和测试逻辑是否准确,会直接影响模型接收到的优化信号。
一旦数据存在指令与测试不一致、验证缺项、环境构造失真或容错设置不合理等问题,模型学到的就不再是目标能力本身,而是如何适应有缺陷的评测机制。这类问题会直接污染 Reward 信号,带来假阳性、假阴性、奖励作弊和错误收敛,最终使训练结果与模型真实能力发生偏离。
本文随机抽取 12 个SETA 开源数据进行拆解,重点分析这类缺陷如何破坏任务的可解性与可验证性,以及它们为什么不适合作为高质量训练数据进入 RLVR 范式训练流程。
典型案例拆解
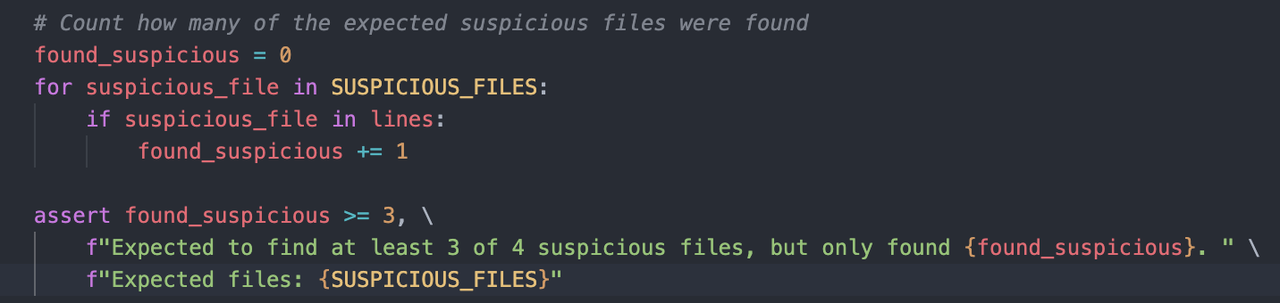
Case 1|Harbor-Dataset/292:测试标准被放宽,部分命中也可通过
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/292
问题归类:测试断言标准被刻意放宽,并且测试逻辑与自然语言指令之间存在明显语义割裂。
分析说明:该任务要求"找出并统计目录下隐藏及可疑文件"(要求 100% 召回),本质上是一个强调完整召回的检测任务;但测试脚本却使用Expected to find at least 3 of 4 suspicious files作为通过标准。也就是说,模型即便遗漏四分之一的目标,也仍可获得正向反馈。对于依赖确定性验证的训练来说,这种"部分命中即通过"的策略会将本应严格的布尔型奖励扭曲为模糊容错,从而引入显著噪声。
影响判断:结果是评测产生假阳性,模型无需完成完整任务即可通过测试,进而诱发 Reward Hacking,削弱样本对真实代码能力的区分度。
Case 2|Harbor-Dataset/1311:验证粒度过粗,无法证明"升级即修复"
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1311
问题归类:测试只校验依赖存在性,未校验版本状态与功能性修复是否真正完成。
分析说明:题目要求通过升级 ansible-core 修复特定问题,但测试脚本仅检查 ansible 是否存在,而没有对目标版本号做精确比对,也没有设计修复后运行行为的回归验证。这样的测试无法回答两个核心问题:模型是否真的执行了升级操作,以及升级是否真正消除了底层故障。
影响判断:在这种设置下,模型仅执行 pip install ansible 一类浅层命令,就可能骗过测试。Benchmark 因而无法区分"真实修复"与"表面满足依赖",评测有效性显著下降。

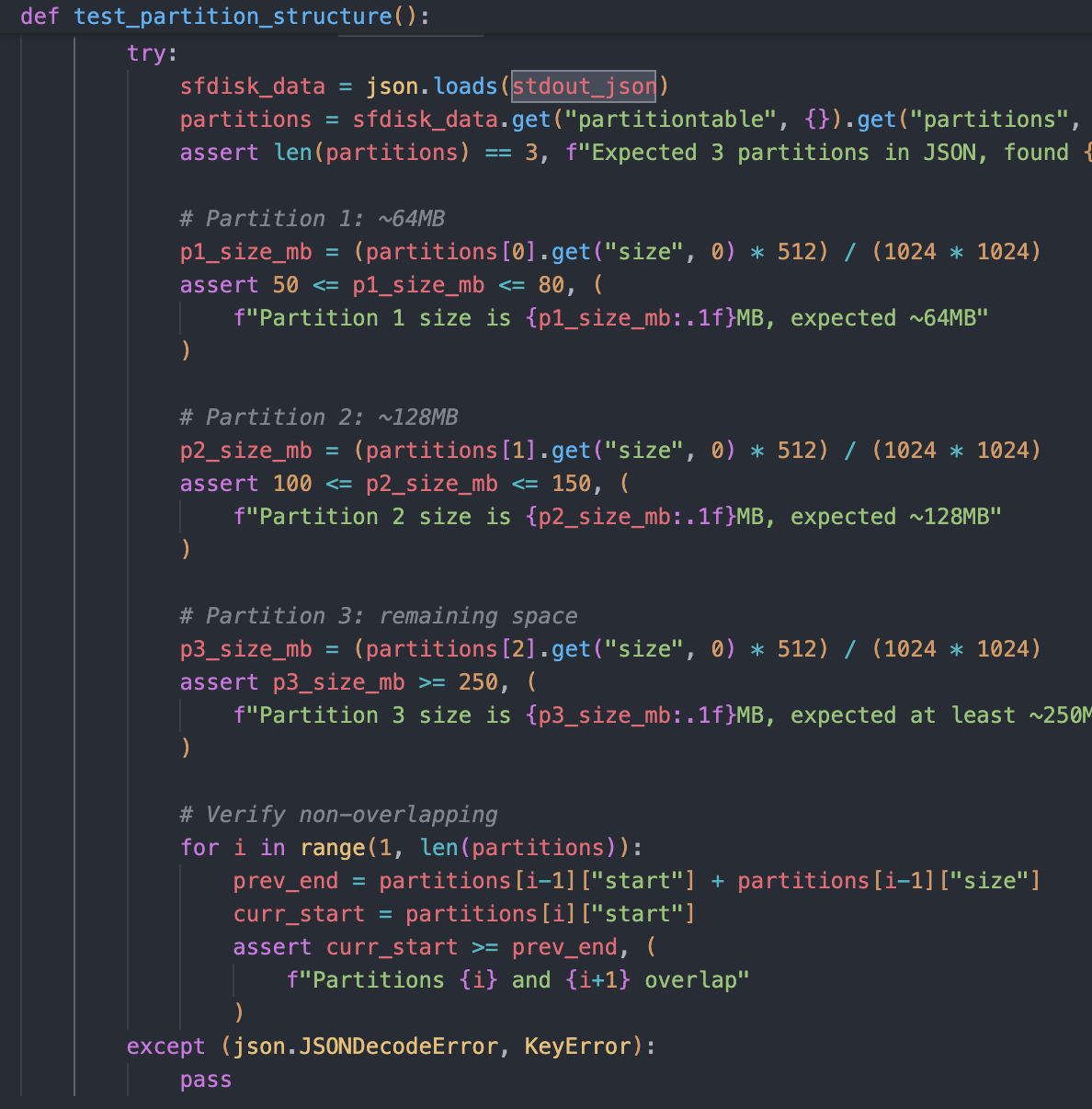
Case 3|Harbor-Dataset/873:数值约束被容差吞没,精确执行能力失去检验
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/873
问题归类:测试对明确数值约束使用宽泛容差,导致精确指令遵循无法被有效验证。
分析说明:该任务明确要求创建 512MB 的磁盘镜像,并划分 64MB、128MB 等精确分区。对于此类具备绝对量化约束的系统任务,测试本应采用严格校验;但样本却使用了较宽的模糊容差。结果是,模型即便未严格按照要求完成分区,甚至未处理好分区对齐问题,也可能获得通过。
影响判断:这会把精确执行任务错误地转化为"差不多即可"的任务,不仅抬高假阳性,也会在训练中产生高方差噪声奖励,破坏模型对精确数值与异常处理逻辑的学习。
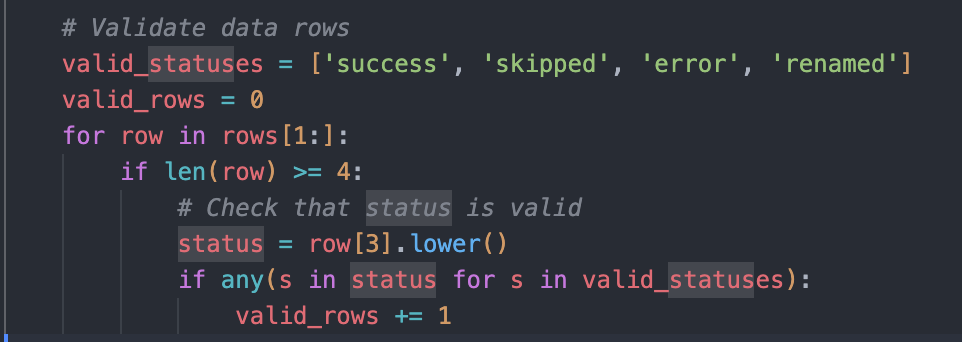
Case 4|Harbor-Dataset/836:隐式规范被硬编码,核心功能却没有被测试
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/836
问题归类:测试脚本额外引入未声明约束,同时遗漏了对核心功能的验证。
分析说明:题目要求实现媒体文件整理与重命名,并明确提出需要支持 --dry-run 模式。但测试脚本却将 success、skipped、error、renamed 等状态枚举硬编码为隐式规范,迫使模型去"猜测"评测器内部口径;与此同时,对 --dry-run 这一关键安全特性却没有任何覆盖。
影响判断:这意味着模型既可能因未猜中隐藏规则而被误判失败,也可能在完全缺失关键功能的情况下侥幸通过。样本的评测逻辑与任务目标发生错位,不适合作为稳定的奖励来源。
Case 5|Harbor-Dataset/82:指令上下文缺失与不可解任务
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/82
问题归类:题目未提供完成任务所需的关键接口规范,导致题目在事实上不可解。
分析说明:该任务要求实现支持 full/safe-upgrade 模式的依赖升级脚本,但测试却隐含依赖特定 CLI 名称、特定 --db 参数以及未公开的 JSON Schema。也就是说,决定程序能否运行的关键契约并未出现在自然语言指令中。模型缺少必要输入规范时,无法凭空猜中测试脚本所期待的黑盒接口。
影响判断:这类数据会稳定地产生假阴性。即使模型具备正确的逻辑设计能力,也会因缺失上下文而被无端惩罚,严重损害训练过程中的探索效率与反馈公平性。

Case 6|Harbor-Dataset/1060:提示过度,系统级任务退化为代码补全
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1060
问题归类:题目向模型泄露了过多路径、文件与修改策略,显著压缩了问题求解空间。
分析说明:在重新编译 OpenSSH 并禁用 Banner 的任务中,指令不仅给出源码路径、安装路径和测试标记,还在 Hints 中直接定位需要修改的 C 文件,并提示了具体策略。环境同时预置了关键依赖和密钥配置。原本应由模型完成的定位、决策与排障步骤,几乎都被提前展开。
影响判断:结果是本应评估系统级 Agent 能力的任务,被降维成了近似代码补全或指令执行任务。高分不能代表模型真实具备复杂终端环境下的自主求解能力。
Case 7|Harbor-Dataset/802:故障注入过于表层,实际环境与任务描述不符
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/802
问题归类:所谓"系统损坏"仅停留在浅层 Mock,且题目描述与实际环境表现不一致。
分析说明:该任务定位于系统诊断与修复,但故障注入的核心操作只是将 update-alternatives 重命名隐藏。这种构造并不形成真正的系统级故障,一条 mv 命令即可恢复。同时,指令声称 apt-get update/install 会报错,实际环境中这些命令却能够正常执行,导致症状层面出现事实冲突。
影响判断:这类数据会同时损害任务信度与推理有效性。模型既没有面临真实复杂故障,又被错误前提干扰判断,评测自然难以可信。
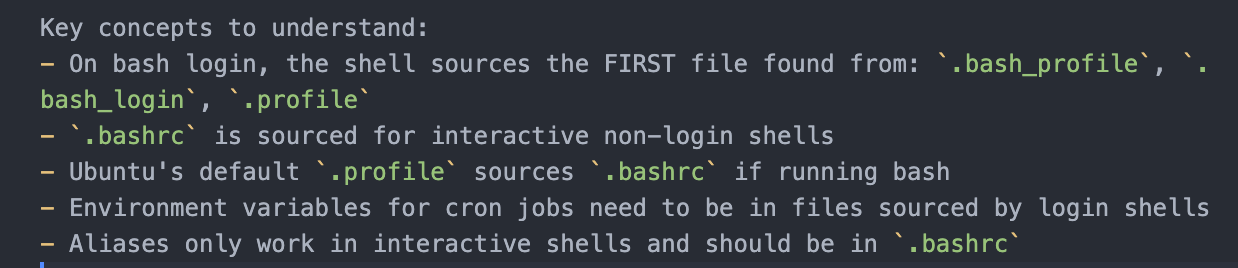
Case 8|Harbor-Dataset/967:过度提示与隐式格式约束同时存在
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/967
问题归类:一方面题目过度透露解题知识,另一方面测试又要求模型猜测未声明的输出格式。
分析说明:在多用户 Shell 环境配置修复任务中,"Key concepts" 已直接给出 Bash 初始化文件优先级等关键知识,显著削弱了任务对诊断与探索能力的要求;但测试在校验 report.txt 时,又采用指令中未说明的硬编码字符串匹配。也就是说,任务在求解阶段"提示过满",在验收阶段"规范缺席"。
影响判断:这种双重失衡会导致任务难度被人为降低,而测试噪声却被人为抬高。最终输出的分数既不能准确反映高阶推理能力,也不能稳定作为训练奖励。
Case 9|Harbor-Dataset/1248:根因泄露与环境简化,制造出"伪 Hard"任务
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1248
问题归类:题目直接泄露根因和命令路径,同时底层环境拓扑又远比真实问题简单。
分析说明:该任务表面上考察 Linux 包依赖冲突诊断,但指令直接透露了 apt-mark hold、版本冲突等核心根因,还列出了 apt-mark showhold 等关键诊断命令及上下文路径。与此同时,环境仅包含少量伪造包与极简线性依赖链,缺乏真实场景中常见的环依赖、PPA 冲突或 Apt Pinning 优先级竞争。
影响判断:当任务同时发生"答案泄露"和"问题简化"时,所谓 Hard 标签就失去意义。模型得到的不是对复杂排障能力的检验,而是一次指令到 Bash 的低难度翻译练习。
Case 10|Harbor-Dataset/701:环境初始化失效,测试退化为静态关键词匹配
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/701
问题归类:环境前置条件未被正确建立,同时测试未验证动态行为,只检查源码表层特征。
分析说明:该任务涉及进程管理与回收,本应验证运行时行为。但由于 Dockerfile 缺失 CMD,初始化脚本没有执行,容器中并不存在题目描述的僵尸进程与 PID 文件。面对这样一个动态系统任务,测试却进一步退化为对 SIGTERM、sleep、kill -- - 等关键词的静态匹配,而非真正执行并观察脚本行为。
影响判断:这会形成"环境不可用、逻辑可作弊"的双重断层。模型既无法在真实问题上操作,又可以通过堆砌关键词通过测试,是合成系统任务中非常典型的质量灾难。
Case 11|Harbor-Dataset/72:答案泄露严重,核心交付物却未被验证
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/72
问题归类:题目点明了几乎所有问题与修复方向,但测试没有验证要求交付的自动化脚本。
分析说明:该任务不仅将无效源、Held 包、依赖冲突等故障类型全部提前说明,还明确要求输出 solution.sh 修复脚本。然而测试只检查最终环境状态,例如目标包是否已安装,而不检查 solution.sh 是否存在、是否可复用、是否具备正确逻辑。
影响判断:这使模型完全可以绕过"写脚本"这一核心工程要求,只靠终端手工修补环境获得通过。任务表面复杂,实则没有有效评估交付能力。
Case 12|Harbor-Dataset/1355:操作手册式题目,基本不考察真实诊断能力
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1355
问题归类:题目把环境、问题、方案与验收一并给出,几乎将求解过程完全程序化。
分析说明:该任务围绕多软件包开发环境中的二进制路径冲突展开,但指令逐项列明了四类问题、各自根因、推荐诊断命令以及需要修改的配置文件,连 HOME 目录和检查路径都明确指出。最终验证还将多条命令的输出精确约束到字符串级别。这样的题目不是在观察模型如何定位问题,而是在要求模型沿着既定步骤完成一套操作流程。
影响判断:与其说这是诊断任务,不如说是一份带答案的操作手册。它可以评估流程执行是否完整,却难以评估模型在陌生环境中的自主发现、假设构建与根因分析能力。
结论
综合这 12 个案例可以看到,SETA任务中的问题并非零散失误,而是呈现出较稳定的结构性模式:要么题目把答案泄露得过多,导致任务难度被系统性降级;要么测试覆盖不足、断言过粗或引入隐藏规范,导致验证目标发生偏移;要么环境本身无法支撑题目宣称的问题设定,最终使样本在"可解性"和"可验证性"两个层面同时失效。
如果此类数据未经严格审查直接进入训练流程,问题不会停留在单点误差,而会进一步转化为系统性的奖励噪声、评测泡沫与优化误导。对于追求高质量代码数据与 Agent 数据的生产流程而言,真正关键的不是"能否快速合成更多数据",而是"能否确保每个任务在指令、环境、测试之间形成严格闭环"。
这也是为什么,数据质量评估不能只看表面复杂度、样本数量或最终 Benchmark 分数,而必须回到任务设计与验证逻辑本身。只有经得起逐题拆解的数据,才有资格进入高价值训练产线。
SETA(Camel-AI 发布):号称全自动生成与验证的 SOTA 级合成数据集。地址:https://github.com/camel-ai/seta-env/
本文基于对 SETA 数据集中12个Terminal Bench任务审查,补充梳理出一些高频质量问题。它们主要集中在指令与测试不对齐、环境构造失真、验证粒度不足、题目信息泄露过度,以及关键能力未被有效考察等方面。对于RLVR的训练范式而言,这类缺陷会直接污染 Reward 信号,误导模型优化方向。
背景与分析目标
RLVR是一类依赖可自动验证结果进行优化的训练方法,在代码生成、终端操作和智能体任务中应用广泛。对于这类方法,测试脚本不仅用于评测模型表现,也直接决定奖励信号的生成方式。换句话说,任务指令、执行环境和测试逻辑是否准确,会直接影响模型接收到的优化信号。
一旦数据存在指令与测试不一致、验证缺项、环境构造失真或容错设置不合理等问题,模型学到的就不再是目标能力本身,而是如何适应有缺陷的评测机制。这类问题会直接污染 Reward 信号,带来假阳性、假阴性、奖励作弊和错误收敛,最终使训练结果与模型真实能力发生偏离。
本文随机抽取 12 个SETA 开源数据进行拆解,重点分析这类缺陷如何破坏任务的可解性与可验证性,以及它们为什么不适合作为高质量训练数据进入 RLVR 范式训练流程。
典型案例拆解
Case 1|Harbor-Dataset/292:测试标准被放宽,部分命中也可通过
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/292
问题归类:测试断言标准被刻意放宽,并且测试逻辑与自然语言指令之间存在明显语义割裂。
分析说明:该任务要求"找出并统计目录下隐藏及可疑文件"(要求 100% 召回),本质上是一个强调完整召回的检测任务;但测试脚本却使用Expected to find at least 3 of 4 suspicious files作为通过标准。也就是说,模型即便遗漏四分之一的目标,也仍可获得正向反馈。对于依赖确定性验证的训练来说,这种"部分命中即通过"的策略会将本应严格的布尔型奖励扭曲为模糊容错,从而引入显著噪声。
影响判断:结果是评测产生假阳性,模型无需完成完整任务即可通过测试,进而诱发 Reward Hacking,削弱样本对真实代码能力的区分度。
Case 2|Harbor-Dataset/1311:验证粒度过粗,无法证明"升级即修复"
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1311
问题归类:测试只校验依赖存在性,未校验版本状态与功能性修复是否真正完成。
分析说明:题目要求通过升级 ansible-core 修复特定问题,但测试脚本仅检查 ansible 是否存在,而没有对目标版本号做精确比对,也没有设计修复后运行行为的回归验证。这样的测试无法回答两个核心问题:模型是否真的执行了升级操作,以及升级是否真正消除了底层故障。
影响判断:在这种设置下,模型仅执行 pip install ansible 一类浅层命令,就可能骗过测试。Benchmark 因而无法区分"真实修复"与"表面满足依赖",评测有效性显著下降。
Case 3|Harbor-Dataset/873:数值约束被容差吞没,精确执行能力失去检验
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/873
问题归类:测试对明确数值约束使用宽泛容差,导致精确指令遵循无法被有效验证。
分析说明:该任务明确要求创建 512MB 的磁盘镜像,并划分 64MB、128MB 等精确分区。对于此类具备绝对量化约束的系统任务,测试本应采用严格校验;但样本却使用了较宽的模糊容差。结果是,模型即便未严格按照要求完成分区,甚至未处理好分区对齐问题,也可能获得通过。
影响判断:这会把精确执行任务错误地转化为"差不多即可"的任务,不仅抬高假阳性,也会在训练中产生高方差噪声奖励,破坏模型对精确数值与异常处理逻辑的学习。
Case 4|Harbor-Dataset/836:隐式规范被硬编码,核心功能却没有被测试
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/836
问题归类:测试脚本额外引入未声明约束,同时遗漏了对核心功能的验证。
分析说明:题目要求实现媒体文件整理与重命名,并明确提出需要支持 --dry-run 模式。但测试脚本却将 success、skipped、error、renamed 等状态枚举硬编码为隐式规范,迫使模型去"猜测"评测器内部口径;与此同时,对 --dry-run 这一关键安全特性却没有任何覆盖。
影响判断:这意味着模型既可能因未猜中隐藏规则而被误判失败,也可能在完全缺失关键功能的情况下侥幸通过。样本的评测逻辑与任务目标发生错位,不适合作为稳定的奖励来源。
Case 5|Harbor-Dataset/82:指令上下文缺失与不可解任务
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/82
问题归类:题目未提供完成任务所需的关键接口规范,导致题目在事实上不可解。
分析说明:该任务要求实现支持 full/safe-upgrade 模式的依赖升级脚本,但测试却隐含依赖特定 CLI 名称、特定 --db 参数以及未公开的 JSON Schema。也就是说,决定程序能否运行的关键契约并未出现在自然语言指令中。模型缺少必要输入规范时,无法凭空猜中测试脚本所期待的黑盒接口。
影响判断:这类数据会稳定地产生假阴性。即使模型具备正确的逻辑设计能力,也会因缺失上下文而被无端惩罚,严重损害训练过程中的探索效率与反馈公平性。
Case 6|Harbor-Dataset/1060:提示过度,系统级任务退化为代码补全
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1060
问题归类:题目向模型泄露了过多路径、文件与修改策略,显著压缩了问题求解空间。
分析说明:在重新编译 OpenSSH 并禁用 Banner 的任务中,指令不仅给出源码路径、安装路径和测试标记,还在 Hints 中直接定位需要修改的 C 文件,并提示了具体策略。环境同时预置了关键依赖和密钥配置。原本应由模型完成的定位、决策与排障步骤,几乎都被提前展开。
影响判断:结果是本应评估系统级 Agent 能力的任务,被降维成了近似代码补全或指令执行任务。高分不能代表模型真实具备复杂终端环境下的自主求解能力。
Case 7|Harbor-Dataset/802:故障注入过于表层,实际环境与任务描述不符
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/802
问题归类:所谓"系统损坏"仅停留在浅层 Mock,且题目描述与实际环境表现不一致。
分析说明:该任务定位于系统诊断与修复,但故障注入的核心操作只是将 update-alternatives 重命名隐藏。这种构造并不形成真正的系统级故障,一条 mv 命令即可恢复。同时,指令声称 apt-get update/install 会报错,实际环境中这些命令却能够正常执行,导致症状层面出现事实冲突。
影响判断:这类数据会同时损害任务信度与推理有效性。模型既没有面临真实复杂故障,又被错误前提干扰判断,评测自然难以可信。
Case 8|Harbor-Dataset/967:过度提示与隐式格式约束同时存在
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/967
问题归类:一方面题目过度透露解题知识,另一方面测试又要求模型猜测未声明的输出格式。
分析说明:在多用户 Shell 环境配置修复任务中,"Key concepts" 已直接给出 Bash 初始化文件优先级等关键知识,显著削弱了任务对诊断与探索能力的要求;但测试在校验 report.txt 时,又采用指令中未说明的硬编码字符串匹配。也就是说,任务在求解阶段"提示过满",在验收阶段"规范缺席"。
影响判断:这种双重失衡会导致任务难度被人为降低,而测试噪声却被人为抬高。最终输出的分数既不能准确反映高阶推理能力,也不能稳定作为训练奖励。
Case 9|Harbor-Dataset/1248:根因泄露与环境简化,制造出"伪 Hard"任务
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1248
问题归类:题目直接泄露根因和命令路径,同时底层环境拓扑又远比真实问题简单。
分析说明:该任务表面上考察 Linux 包依赖冲突诊断,但指令直接透露了 apt-mark hold、版本冲突等核心根因,还列出了 apt-mark showhold 等关键诊断命令及上下文路径。与此同时,环境仅包含少量伪造包与极简线性依赖链,缺乏真实场景中常见的环依赖、PPA 冲突或 Apt Pinning 优先级竞争。
影响判断:当任务同时发生"答案泄露"和"问题简化"时,所谓 Hard 标签就失去意义。模型得到的不是对复杂排障能力的检验,而是一次指令到 Bash 的低难度翻译练习。
Case 10|Harbor-Dataset/701:环境初始化失效,测试退化为静态关键词匹配
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/701
问题归类:环境前置条件未被正确建立,同时测试未验证动态行为,只检查源码表层特征。
分析说明:该任务涉及进程管理与回收,本应验证运行时行为。但由于 Dockerfile 缺失 CMD,初始化脚本没有执行,容器中并不存在题目描述的僵尸进程与 PID 文件。面对这样一个动态系统任务,测试却进一步退化为对 SIGTERM、sleep、kill -- - 等关键词的静态匹配,而非真正执行并观察脚本行为。
影响判断:这会形成"环境不可用、逻辑可作弊"的双重断层。模型既无法在真实问题上操作,又可以通过堆砌关键词通过测试,是合成系统任务中非常典型的质量灾难。
Case 11|Harbor-Dataset/72:答案泄露严重,核心交付物却未被验证
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/72
问题归类:题目点明了几乎所有问题与修复方向,但测试没有验证要求交付的自动化脚本。
分析说明:该任务不仅将无效源、Held 包、依赖冲突等故障类型全部提前说明,还明确要求输出 solution.sh 修复脚本。然而测试只检查最终环境状态,例如目标包是否已安装,而不检查 solution.sh 是否存在、是否可复用、是否具备正确逻辑。
影响判断:这使模型完全可以绕过"写脚本"这一核心工程要求,只靠终端手工修补环境获得通过。任务表面复杂,实则没有有效评估交付能力。
Case 12|Harbor-Dataset/1355:操作手册式题目,基本不考察真实诊断能力
案例链接:https://github.com/camel-ai/seta-env/tree/main/Harbor-Dataset/1355
问题归类:题目把环境、问题、方案与验收一并给出,几乎将求解过程完全程序化。
分析说明:该任务围绕多软件包开发环境中的二进制路径冲突展开,但指令逐项列明了四类问题、各自根因、推荐诊断命令以及需要修改的配置文件,连 HOME 目录和检查路径都明确指出。最终验证还将多条命令的输出精确约束到字符串级别。这样的题目不是在观察模型如何定位问题,而是在要求模型沿着既定步骤完成一套操作流程。
影响判断:与其说这是诊断任务,不如说是一份带答案的操作手册。它可以评估流程执行是否完整,却难以评估模型在陌生环境中的自主发现、假设构建与根因分析能力。
结论
综合这 12 个案例可以看到,SETA任务中的问题并非零散失误,而是呈现出较稳定的结构性模式:要么题目把答案泄露得过多,导致任务难度被系统性降级;要么测试覆盖不足、断言过粗或引入隐藏规范,导致验证目标发生偏移;要么环境本身无法支撑题目宣称的问题设定,最终使样本在"可解性"和"可验证性"两个层面同时失效。
如果此类数据未经严格审查直接进入训练流程,问题不会停留在单点误差,而会进一步转化为系统性的奖励噪声、评测泡沫与优化误导。对于追求高质量代码数据与 Agent 数据的生产流程而言,真正关键的不是"能否快速合成更多数据",而是"能否确保每个任务在指令、环境、测试之间形成严格闭环"。
这也是为什么,数据质量评估不能只看表面复杂度、样本数量或最终 Benchmark 分数,而必须回到任务设计与验证逻辑本身。只有经得起逐题拆解的数据,才有资格进入高价值训练产线。