Rubric 第三讲:如何科学的设计和优化 rubric
在本系列博客的第一篇中,我们介绍了基于评分量表(Rubrics)的评估方法,以及这一方法如何同时提升自动化评估与人工评估的可靠性;第二篇则深入分析了不同类型的评分量表及其适用场景,包括可能需要逐步评估的智能体(Agentic Systems)场景。
本篇将从更深的层面出发:结合我们与客户的实践经验、内部实验,以及跨越 AI 与教育学的经典研究,解释——评分量表为什么能够工作?它背后的“科学”是什么?
本文将重点关注以下三个方面:
- 如何设计结构化评分量表
- 如何衡量评分量表的质量
- 如何提升评分量表的质量
本文的核心观点的是:评分量表不是独立存在的“规定”,其本质目的是通过以下两种方式实现价值预测:(1)与目标用户的目标保持一致;(2)最大化不同评分者之间的一致率。

仅在某一个维度上用力往往是不够的——如果评估标准只强调“对齐目标”,但定义含糊、解释空间过大,最终会在样本层面出现严重的评分分歧;反过来,如果我们过度追求评分者之间的高一致率,也容易得到过于表层、缺乏判别力的标准,无法真正反映任务对模型能力的要求。
因此,在评分量表设计的科学体系中,我们将评分量表视为一种 “模型”,并通过迭代优化其设计,同时实现上述两个维度的优化目标。
一、评分量表的结构化设计
本节将拆解有效评分量表结构的核心要素,并探讨如何调整这些要素,以适应细粒度评估和奖励建模的需求。
(一)支持细粒度评估的结构
在设计细粒度评估的评分量表时,首要任务是明确希望评估者提供的评估形式。道森(Dawson)等人 [3] 提出了 14 个评估时需考虑的评分量表设计要素,其中与评分量表结构密切相关的四个要素如下:
- 评估标准:指评分量表中用于衡量 “质量属性” 的具体指标。即要评什么、逻辑是否自洽、事实是否准确、步骤是否可执行。
- 特异性:评分量表从通用到高度专属呈梯度分布。通用型评分量表可用于多个任务实例;高特异性的标准则针对某个具体任务实例定制,能提供更细致、精准的反馈。两者在实际项目中常需要配合使用。
- 质量等级:指评估者在评估过程中可选用的有序分类。例如,某一标准可采用 “通过 / 不通过” 的二元等级,也可采用李克特量表(Likert Scale)这类包含不同同意程度的多等级评分体系。
- 配套反馈信息:评估者给出的评分理由往往具有重要价值。既可作为模型的额外反馈,也可用于评分量表的质量保障。
在设计评分量表的 “特异性” 和 “质量等级” 时,设计者常会面临类似的决策难题。以下几点有助于提升评分量表的有效性:
- 量表点数:通常建议采用 5–7 个量表点,既能提供足够的区分度,又不会增加评估者负担。若使用二元量表,则需给出明确的通过/不通过标准,以避免解读偏差。
- 奇偶数量选择:奇数点量表允许评估者选择中立项,但可能被滥用来规避判断;偶数点量表能促使评估者表态,却可能让真正中立的情况无处安放。
- 平衡且带标签的量表:优质量表应在正负方向上保持数量平衡,并使用对称、力度相当的表述。若一侧措辞更强,会潜在影响评估者的选择方向。
- 评分量表的复杂性:过于冗长或操作繁琐的标准容易引发评估疲劳,表现为重复作答、随意作答或中途放弃。因此应在细致度与评估成本之间做好取舍。
为降低歧义,更复杂的评分结构正被逐渐采用。这类结构不仅让设计者提供更强的控制力,还能满足新方法的需求。因此,我们开始看到越来越多结构化、更可控、同时能提供细粒度信息的新型 Rubric。例如下一节将详细讨论 PaperBench 采用的“层级 Rubric”结构。
层级结构:PaperBench 的示例
PaperBench 的 Rubric 将“复现论文”分解为由粗到细的多个层级,最底层为客观、可操作的子节点,如:
- 结果是否匹配
- 代码是否可执行
- 对论文中某个贡献是否完整实现
每个子项都有权重,最终合成总得分。这类结构不仅客观,更能对“部分完成”的尝试给予合理奖励,对智能体任务尤为重要。
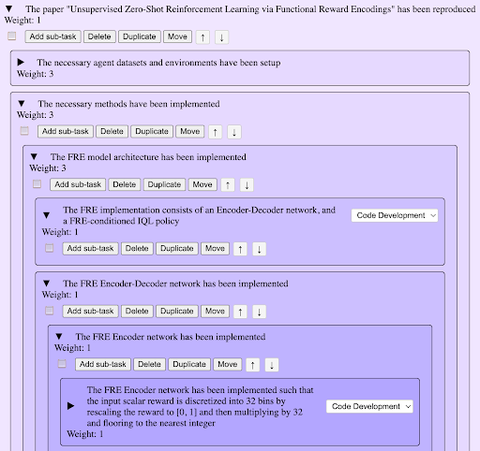 图 1:PaperBench 基准测试中某篇论文的评分量表节选 [8]
图 1:PaperBench 基准测试中某篇论文的评分量表节选 [8]
(二)支持学习算法的结构
细粒度评估的结构也适用于学习算法,但学习算法有两个额外挑战:(1)在大多数学习应用中,评分量表的信号最终会被简化为一维输出,例如"好/坏";(2)在涉及数千个、甚至更多评估步骤的学习循环中,完全依赖人工评估并不现实,必须可自动化。
因此,我们需要:
- 使用 LLMAJ(LLM as a Judge)自动应用评分量表
- 使用模型自我批判(Self Critiques)与自我修订
- 从人类/LLM 标注生成监督信号,训练轻量奖励模型
早期 RLHF 工作采用相对扁平的评分量表,由人工标注偏好对以训练奖励模型。相比之下,Bai 等人 [2] 在“宪法式人工智能(Constitutional AI, CAI)”中首次提出更具可扩展性的评分量表设计方式:将一组简洁的原则通过提示注入模型,使其能够利用规则进行自我批判和自我改写,旨在提升 LLM 的有用性、无害性和诚实性。两类核心提示包括:
- 批判请求:找出助手回复中所有有害、不道德或带有社会偏见的内容,并说明应如何改进。
- 修订请求:重写回复,去除所有有害、不道德或带偏见的内容,并引导对话朝积极方向发展。
这些原则表达简洁,但其具体语义需由模型在上下文中自行推断,实现了规则的高扩展性。
在此基础上,后续大量 RLAIF(AI 反馈强化学习)方法进一步发展评分量表结构。这些方法通常会利用评分量表引导模型生成反馈。例如,Srivastava 等人 [7] 提出的 因果稳健奖励建模(Crome,Causal Robust Reward Modeling)使用因果评分量表区分真正影响质量的要素与不应影响结果的虚假因素。
该方法通过与模型交互自动挖掘候选属性、审查其合理性,并据此扩展奖励模型训练数据。实验表明:
- 在 RewardBench 上整体准确率提升 5.4%;
- 在含虚假属性的对抗样本与长尾输入中失败率显著下降;
- 评分量表结构有助于对奖励模型进行细粒度性能诊断。
二、衡量评分量表的质量
Rubric 的质量不是靠感觉,而是可量化的。定量指标能帮助系统地评估评分量表的有效性、加速迭代,并减少对耗时的人工审查的依赖。但这些指标必须与实际应用场景和下游任务的效果直接相关。
Rubric 设计的一个核心目标是提升"标注者间一致率"(或"评分者信度"),即不同评分者独立判断时的一致程度 [4,9]。例如,"联合一致概率"可以估计评分者达成一致的比例,但它没有考虑"偶然一致"的情况。Cohen's Kappa、Fleiss' Kappa 等指标则在计算中考虑了随机因素,因而更可靠[4,9]。
(一)评分者一致率
大量研究表明,相比无指导评分,使用 Rubric 可显著提高人工评分者的“评分者间一致率”[5]。统一的评分量表能使评分更趋一致,但这种一致率并非自动形成,仍需通过统计指标来评估并指导改进。
例如,在 HealthBench 的开发中,尽管研究团队严格筛选医生并持续进行定性评估,评分一致率仍只有 55%–75% [1]。作者推测,这可能源于评分量表模糊、任务存在歧义,或评分者在专业背景、风险偏好、沟通风格等方面不同。
(二)单个评分者的一致率
Rubric 也能提升单个评分者的稳定性,即"评分者内部一致率"。一项研究综述发现,通过克朗巴赫阿尔法系数(Cronbach's alpha)衡量,评分量表通常能带来更高的内部一致率 [5]。原因在于 Rubric 为每个分值区间提供了固定参照,从而稳定了评分者的判断。
(三)人类与 LLMAJ 的一致率
在使用 AI 进行基于 Rubric 的自动评分时,如上文提及的学习算法场景,“人类标注者与 LLMAJ 的评分量表一致率” 是另一关键指标。用于衡量评分者一致率的统计方法同样适用于评估模型。例如,Sirdeshmukh 等人 [6] 在 MultiChallenge 基准中采用“实例级 Rubric 评估”,在引入评分量表后,LLMAJ 与人类的一致率从 37.3% 提升至 93.95%。
(四)与最终目标的一致率
最后,本文开篇即提出,评分量表的优化需关注第二个维度 —— 与整体目标的一致率。从衡量角度而言,这本质上是与 “最终用户”(即深入理解甚至制定原始问题的人群)的一致率。在实践中,这通常意味着:确定一个能代表目标的小型群体,并应用上述一致率指标进行衡量。但从组织层面看,这一过程常受跨团队沟通等因素影响。下文在讨论“定性优化”时,将进一步说明如何在完善 Rubric 的同时,更好地对齐整体目标。
三、提升评分量表的质量
Rubric 能实现专业、细致、可扩展的评估,但其有效性取决于 Rubric 本身的质量。表述含糊的 Rubric 会导致评估失效;反之,经过系统优化的 Rubric 则能成为高质量、人机共同参与评估的基础。
提升 Rubric 质量可通过两条路径进行:定量优化与定性优化。
(一)定量优化
若将 Rubric 视作一种“模型”,则其改进可以沿用模型开发流程:冻结 AI 系统及相关输出,优化评分量表本身,并通过迭代衡量(进而提高)上述一致率与目标对齐度。
这一过程遵循所有数据科学的基本原则。例如,在优化评分量表时,需预留足够的测试数据,避免过度拟合小样本;并可通过人工或 AI 辅助方式对 Rubric 进行增删和重写,同时优化相关衡量指标。显然,要让这一过程生效,下一步需明确 “如何基于评估结果与衡量指标更新评分量表”—— 这就涉及到循环中的关键环节:定性处理。
(二)定性优化
在理想情况下,Rubric 应由专家团队多轮协作开发。近期的基准测试(如 HealthBench 和 PaperBench)充分体现了系统定性流程的价值 [1,8]:
- HealthBench 基于 5000 组医疗多轮对话构建,包含超过 48000 个独特的评分量表,用于评估模型回复质量;
- PaperBench 通过人工定制的评分量表,评估人工智能体复现 20 篇 2024 年国际机器学习大会(ICML)论文的能力。
两个项目均深度联合领域专家,通过人工方式构建、评估并优化评分量表,但这一过程成本巨大。例如,PaperBench 的作者提到,制定一篇论文的 Rubric 通常需要与原作者反复沟通,耗时数周。
为了确保质量,这些项目首先严格筛选专家:
- HealthBench 从 1021 名医生中筛选出 262 名;
- PaperBench 仅邀约获得“亮点报告(Spotlight)” 或 “口头报告(Oral)” 的论文。
随后,他们建立了多轮审查与严格的质量监控机制,例如 PaperBench 要求每篇论文的评估必须在 15 分钟内完成。
这些实践共同指出:Rubric 的可靠性不仅来自“写得好”,还来自谁在使用以及如何使用。因此,评估者的筛选与培训至关重要,可减少偏见并提升一致率。
教育学、心理学与社会科学长期研究显示,人类评估行为受到多种偏见影响,例如:
- 趋中偏见:评分者倾向于避免选择极端分数,而将评分集中在中间等级。这种现象在李克特量表数据中尤为常见 ——“强烈同意” 或 “强烈反对” 等极端选项的选择频率远低于中等选项。
- 宽松 / 严苛偏见:部分评分者可能在所有评估中始终给出偏高或偏低的分数。
- 晕轮效应:评分者对评估对象的整体印象会影响其对具体标准的评分。
- 锚定效应:评分者过度依赖最初信息(如第一条样本)。
- 相似性与确认偏见:评分者可能对与自身观点或预期一致的回复给予更高分数。
- 顺从偏见:评估者在不确定时,倾向于同意任何表述,而非客观判断。
- 社会期望偏见:评估者为塑造良好自我形象,会选择 “社会普遍认可” 的答案,而非真实想法。
因此,Rubric 的定性优化不只是“把标准写清楚”,而是一个持续减少偏差、提升一致率、确保目标对齐的系统化过程。通过更精确的标准定义和合理的量表设计,可以在一定程度上缓解这些问题,使评分结果既更一致,也更贴近真实任务需求,从而实现本文开篇强调的双重优化目标。
四、总结
在本系列博客的第三篇中,我们从结构、衡量到优化完整讨论了 Rubric 的科学方法论。Rubric 不应被视为静态的规定,而应被视为可迭代的预测模型——其目标是:
- 与目标用户的任务目标保持一致
- 在不同评分者之间保持一致
有效的 Rubric 设计始于结构化:将评估标准整合为“粒度层级体系”。在初始结构确定后,需要通过迭代不断优化评分量表,同时提升其与目标的对齐度和专家间一致率。在这一过程中,既运用“标注者间一致率”“评分者内部一致率”等定量指标,也结合专家协作与审查进行定性优化。
一面千识通过将定量评估与领域专家的严格定性评审相结合,确保评估既可靠可复现,又始终与系统核心目标保持一致。
References
- Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quinonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. HealthBench: Evaluating large language models towards improved human health. arXiv, 2025.
- Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernan-dez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. Constitutional AI: Harmlessness from AI feedback. arXiv, 2022.
- Phillip Dawson. Assessment rubrics: towards clearer and more replicable design, research and practice. Assessment & Evaluation in Higher Education, 2015.
- Encord. Inter-rater reliability: Definition applications. URL https://encord.com/blog/inter-rater-reliability/. Accessed on July 14, 2025.
- Anders Jonsson and Gunilla Svingby. The use of scoring rubrics: Reliability, validity and educational consequences. Educational Research Review, 2(2): 130–144, 2007.
- Ved Sirdeshmukh, Kaustubh Deshpande, Lifeng Jin Johannes Mols, Ed-Yeremai Cardona, Dean Lee, Jeremy Kritz, Willow Primack, Summer Yue, and Chen Xin. MultiChallenge: A realistic multi-turn conversation evaluation benchmark for frontier LLMs. arXiv, 2025.
- Pragya Srivastava, Harman Singh, Rahul Madhavan, Gandharv Patil, Sravanti Addepalli, Arun Suggala, Rengarajan Aravamudhan, Soumya Sharma, Anirban Laha, Aravindan Raghuveer, Karthikeyan Shanmugam, and Doina Precup. Robust reward modeling via causal rubrics. arXiv, 2025.
- Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Chan Jun Shern, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating AI’s ability to replicate AI research. arXiv, 2025.
- Wikipedia contributors. Inter-rater reliability. URL https://en.wikipedia.org/wiki/Inter-rater_reliability. Accessed: 2025-07-14.