在智能体(Agent)应用中,HITL(Human-in-the-Loop)打开了人类智慧介入 Agent 运转系统的大门。通过HITL用户可以更好地调整Agent的运行轨迹,同时人类智慧的注入也会为模型智能进步提供不可替代的动力。通过 HITL, Agent 可以得到来自两方面的知识:
- 来自AI产品中海量用户产生的反馈数据
- 由专业人士进行的专家知识与数据精炼
市场上大量的AI应用已经有意识地在产品中注入用户反馈的收集策略,但是对于如何让专家参与到产品模型能力迭代的工作中却没有工业化的体系。本文将讨论用户反馈和专家知识的特点与价值,以及专家知识的介入如何补齐产品迭代数据飞轮的最后一块拼图。
用户反馈 vs. 专家知识
参考 Dual process theory:用户反馈往往来自System 1的直觉反应,而专家知识来自 System 2的深度分析。
用户反馈:对齐用户偏好,优化产品体验的“罗盘”
- 数据形式:当用户修正AI的回答、追问细节,或对结果进行点赞/点踩时,这些即时的、自发的行为便构成了模型效果的直接反馈信号
- 核心价值:规模庞大、成本低廉、真实性高 ,能够精确描绘用户的 实际需求分布与产品偏好 。通过收集、清洗并分析这些行为数据,我们能引导模型迭代的方向,持续优化其在真实世界中的对话风格、内容实用性与整体产品体验,使其更懂用户、更好用。
专家知识:突破模型能力上限,定义专业高度
- 生产方式:在专业的工业级平台上,专家们遵循详尽、严谨的规范,进行多轮对话修正、构建高难度评测基准(Benchmark)、或对复杂专业任务进行高质量解决方案构造。
- 核心价值:这一过程产出的数据,具备极高的质量与一致性。它并非简单地满足现有需求,而是旨在系统性地提升模型的逻辑推理、事实准确性和专业领域知识,从而不断推高模型能力的“天花板”,是打造顶尖性能、确保AI专业与可靠的根本保障。
详细的对比
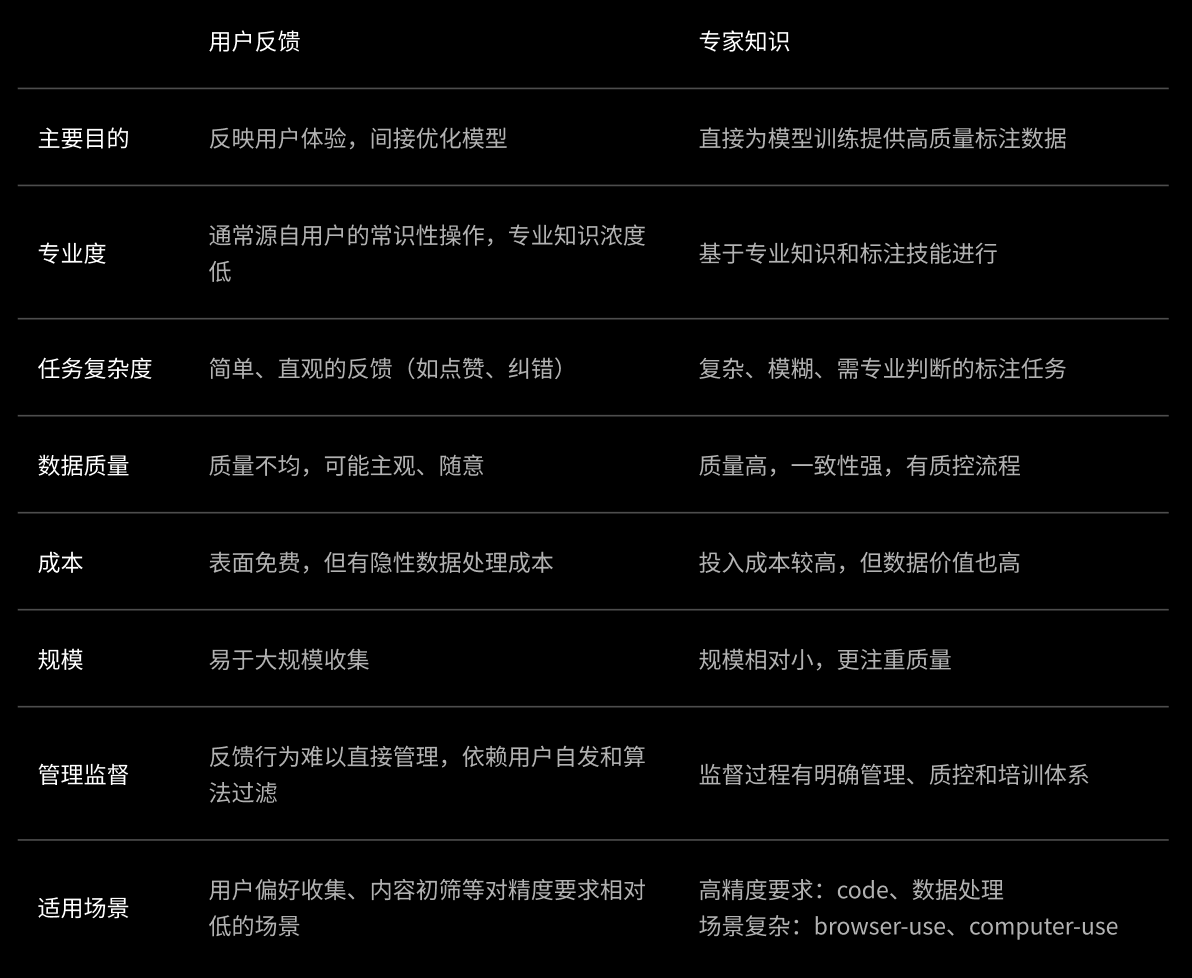
用户反馈的局限性
用户反馈能提供大量数据,但这些数据也存在一些天然的局限:
- 质量不稳定: 用户理解、动机各异,收集的反馈质量参差不齐。
- 缺乏专业性: 用户反馈通常难以处理需要特定领域知识的任务。
- 偏见与噪音: 用户反馈可能带有个人偏见,或因误操作、随意点击产生噪音。
- 任务深度浅: 不适合在产品中嵌入有思考深度的反馈点,影响用户体验。
为何模型的效果提升离不开专家知识
- 高质量数据驱动模型提升: 模型的表现直接取决于训练数据的质量。专家知识是高质量数据产出的核心保障。
- 应对复杂和专业领域: 在医疗、金融、法律等领域,模型的效果强依赖于对专业数据的精准理解和标注。
- 专家评估的权威性: 专家在benchmark 上对 模型/Agent 做的权威评估,对效果迭代有着不可或缺的指导作用。
- 控制长期成本与风险: 初期在高质量数据上的投入,可以减少后期因模型表现不佳带来的修改成本和潜在风险。
- 推动AI合规的发展: 在消除数据偏见、确保AI伦理和合规性方面,专家知识发挥着重要作用。
XpertStudio 如何帮助模型/Agent构建高质量的“专家知识”数据
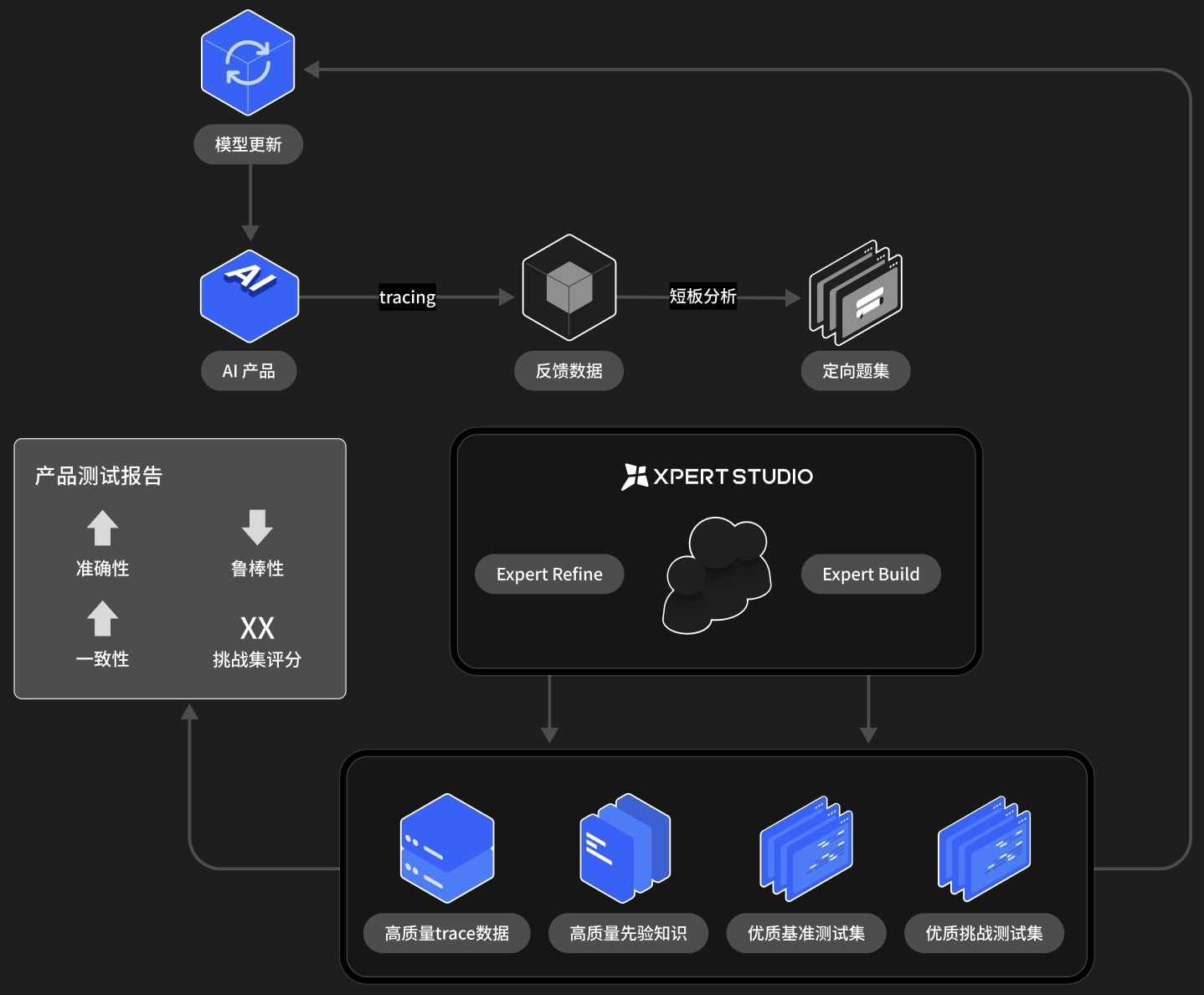
蒸馏反馈数据
提升反馈数据的纯度与价值
- 设定清晰的质量标准: 定义何为“高质量”数据。这包括制定详尽的标注规范、判断标准和一致性要求,形成后续所有优化工作的“度量衡”。
- 逐例校准与深度修正: 专家进行细致的校正与审核。这可能包括修正错误标签、补充缺失信息、统一模糊表述,同时每个例子都会经过多位专家评估,确保每一条数据都符合预设的质量标准。
- 反馈闭环与规则迭代: 在优化过程中发现的共性问题或规则不明确之处,应及时反馈并用于迭代质量标准指南,从而持续提升后续数据处理的效率与准确性。
补齐先验知识
补齐复杂、边缘、深度领域知识先验知识
- 设计针对性的采集与标注方案: 针对知识盲区,专家会设计专门的数据标注流程和定向的query集,确保能够捕捉到这些复杂案例的核心特征与判别信息。
- 构建权威“挑战集”与验证基准: 由专家精心构建的复杂案例集,不仅能直接用于模型训练以提升其处理复杂情况的能力,还能作为权威的“测试集”或“挑战集”,用于更准确地评估和验证模型的鲁棒性与泛化能力。
- 基准集:模型产品当前应该达到的能力,可以作为模型能力评估基准、模型迭代护栏指标。
- 挑战集:模型产品下一迭代需要达到的能力,可以作为模型能力上限探测、RLVR训练数据。